线性结构
线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系
比如数组、链表
非线性结构一般未一对多的形式
比如树、多维数组、图结构
双向链表
双向链表,又稱為双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。 所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。 一般我们都构造双向循环链表。
循环队列
队列:是一种可以分别在两端进行增删的特殊线性表。既然是线性表,那么可以使用顺序存储和链式存储来实现
对于链式存储结构,删减和增加元素的操作比较方便
但是对于顺序存储结构,在队头进行删除的时候,会涉及到迁移操作(删除队头,所有元素都要往前移动),此事的解决方案就是循环队列(同时避免了时间复杂度的提升和空间的浪费)
front是指向头结点的指针,rear是指向下一个要插入结点的指针
值得注意的是:
- 满的判断条件应为:(rear+1)%LENGTH == front 。
- 空的判断条件为 rear == front。
链表VS数组
数组优点:访问速度快,内存为连续的区域
链表优点:插入、删除方便,大小不定,动态添加
为什么JS中的数组时可以动态转变大小?
- JavaScript 中的数组,本质上还是对象,不过用了 Integer Index 的键名而已,和对象并没有什么本质的区别
堆
堆(Heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵完全二叉树的数组对象。
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
完全二叉树的特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。需要注意的是,满二叉树肯定是完全二叉树,而完全二叉树不一定是满二叉树。 [1]
Min-heap: 父节点的值小于或等于子节点的值;
Max-heap: 父节点的值大于或等于子节点的值;
堆和二叉搜索树的区别
堆并不能取代二叉搜索树,它们之间有相似之处也有一些不同。我们来看一下两者的主要差别:
- 节点的顺序。在二叉搜索树中,左子节点必须比父节点小,右子节点必须必比父节点大。但是在堆中并非如此。在最大堆中两个子节点都必须比父节点小,而在最小堆中,它们都必须比父节点大。
内存占用。普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配内存。堆仅仅使用一个数据来存储数组,且不使用指针。
平衡。二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(log n)。你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足堆属性即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(log n) 的性能。
搜索。在二叉树中搜索会很快,但是在堆中搜索会很慢。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作。
数组偏移量
数组偏移量:数组的标准定义为:一个存储元素的线性集合(collection),元素可以通过索引来任意存取,索引通常为数字,用来计算元素存储位置的偏移量
如果你有了解过其他语言,就会知道所有编程语言都有类似的数据结构。但javascript的数组和其他语言有所不同。
JavaScript中的数组是一种特殊的对象,索引为该对象的素性,索引可能是整数。然而,这些数字索引在内部被转换为字符串类型,这是因为JavaScript对象的属性名必须是字符串类型。
JS的存储
资料基本是这样说的: 基本数据类型用栈存储,引用数据类型用堆存储。
但是还得补充:闭包变量书存储与堆中的,毕竟函数被调用完之后,栈顶空间销毁,但是闭包还得存在
对于系统栈来说,调用以下函数
function f(a) {
console.log(a);
}
function func(a) {
f(a);
}
func(1);func + func的上下文压入栈底 ->
f + f的上下文压入栈底 ->
执行完毕f,对应的栈顶空间被回收 ->
执行完func,对应的栈顶空间被回收
修改变量的时候(基本数据类型) : 在当前空间栈开辟一个地址,并且赋予一个值,然后修改原本变量的的地址
如下面的foo变量
let foo = 1;
let bar = 2;
let obj = {
foo: 1,
bar: 2
};
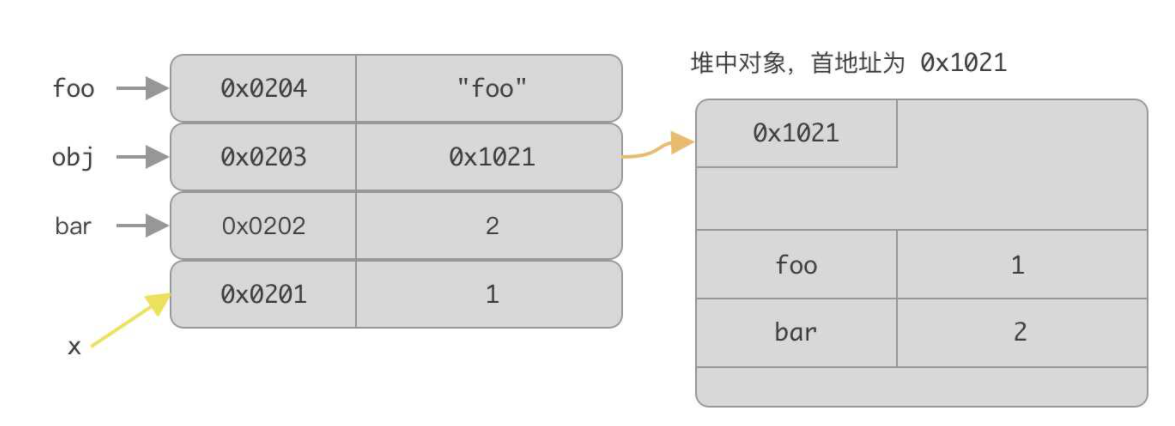
let x = foo
foo = 'foo' //将 foo 的引用地址修改为 0x0204。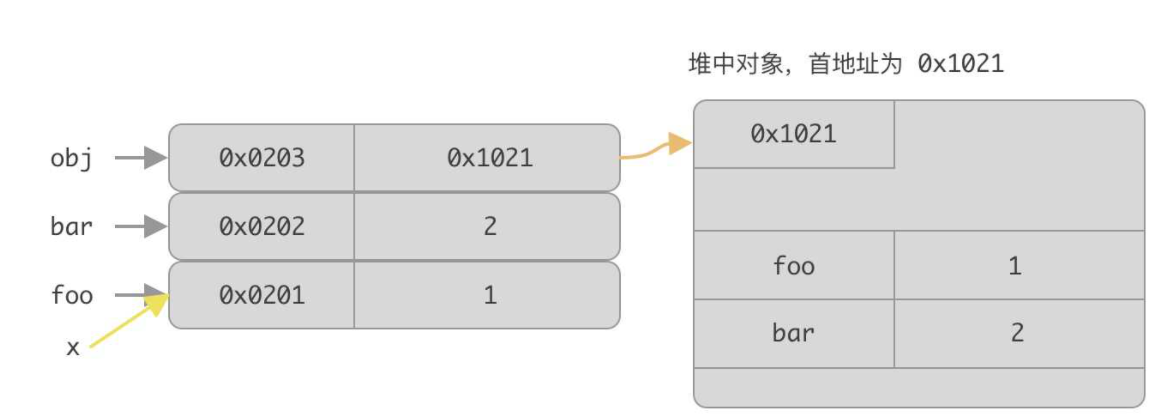
如果碰到const,则会
const foo = 'foo';
foo = 'bar'; // Error
推荐链接https://blog.csdn.net/weixin_40013817/article/details/103287271
JAVA的HashMap
HashMap是一个数组+链表的结合,通过key计算哈希值,放入“桶”,如果当前桶已经存放过,则将以链表的形式加入桶的后面
当每个桶的链表只有一个元素的时候,则存储效率最高,但如果链表过长(碰撞次数过多),则十分不理想
优化hash算法:
初始化
HashMap中Hash算法减少碰撞的两个做法:
Hash方法中存在奇怪的位移运算,以使最终的Hash值中0和1较为均匀。
使用h & (length-1)来进行桶的定位,length应为2的指数幂。
为什么当HashMap初始化大小为2的指数幂时,效率最高?
h&(length-1)原理时,比如和14(1110) 进行与运算,0001、0011、0101、1001、1011、0111、1101这几个位置永远都不能存放元素,空间浪费相当大
- 回头看一下
HashMap中默认的数组大小,查看源代码可以得知是16,为什么是16而不是15,也不是20呢?因为16是2的整数次幂,在数据量小的情况下16比15和20更能减少碰撞,进而提高查询的效率。
扩容
当HashMap中的元素越来越多的时候,碰撞的概率也就越来越高(因为数组的长度是固定的),所以为了提高查询效率,就要对 HashMap 的数组进行扩容
当HashMap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,loadFactor 的默认值为0.75。也就是说,在默认情况下,数组大小为16,当HashMap中元素个数超过16×0.75=12的时候,就把数组的大小扩展为2×16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。


