1.BFF
Back-end for Front-end,服务于前端的后端
BFF就是老生长谈的中间层概念,初衷是在后台服务与前端之前添加一层,比如在中间加上一个node.js,做到请求的转发 和 数据的转换,Nodejs既配合了前端技术栈,也更适应向微服务的并发请求
BFF作为中间层,优点是:
- 前后端彻底分离,即便是后期有微服务迁移,也不需改动前端代码
- 业务更向前靠拢,琐碎的api由前端开发自己决定,更适配前端框架
- BFF可以自开mock,插件也能生成API文档,相比后端单开这类服务要方便些吧
- 留给后端更清晰的服务边界,只需要提供粗粒度的接口即可
缺点:
- 中间层转发会增加请求延迟。
- 需要保证端到端测试
- 必须随时准备好后端异常请求
- BFF分成会增加开发成本

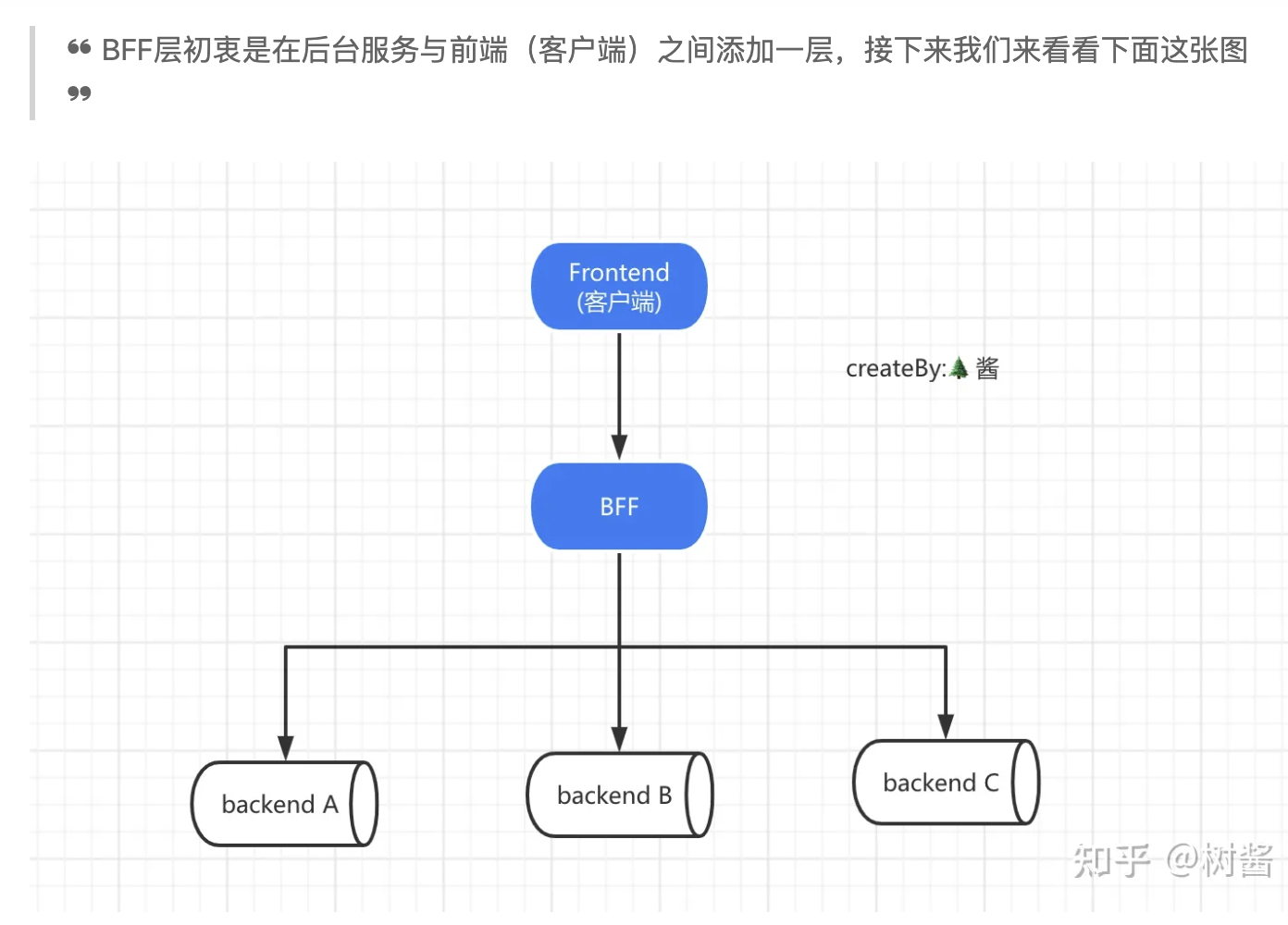
资料来源:https://www.jianshu.com/p/9cca72f9e93c
2.VSCode编译
Emmet语法插件于市面上大多前端编译软件,如VScode所带有的,便于快速写html和CSS
网页移动端适配,开启理想视口,用于做移动端网页的适配
<meta name="viewport" content="width=device-width, initial-scale=1" />h5
想要生成多个标签:div*10,再回车(或者tab),即可生成10个div标签。
生成父子关系标签:div>span,再回车(或者tab),即可生成包含span标签的div标签。
生成兄弟关系标签:div+span,再回车(或者tab)。
输入:.nav 直接生成一个class=“nav”的div标签。(默认div)
输入:#nav 直接生成一个id=“nav”的div标签。
输入:p.nav 直接生成一个class=“nav”的p标签。
输入:.nav$*5 直接生成5个class=“nav1”,class=“nav2”…..的div标签。($是自增符号)
输入:div{前端真好玩}*5 直接生成5个<div> 前端真好玩 </div>
CSS样式内
输入:tac 直接生成text-align: center; 其他语法缩写同样类似,诸如w100—>width: 100
格式化
直接鼠标右键,格式化文档,即可直接让文档变整齐。
(或者想要每次保存后自动格式化,需要在首页—首选项—设置—搜索emmet.include,在setting.json下的用户,添加 “editor.formatOnType”: true, “editor.formatOnSave”: true 即可)
又或者
- On Windows Shift + Alt + F
- On Mac Shift + Option + F
- On Ubuntu Ctrl + Shift + I
生成代码片段
snippet模板网站
https://snippet-generator.app/
然后再vscode中 shift+control+P输入snippet进行代码片段配置,这样我们就可以直接输入我们的前缀(prefix)拿我们的代码片段模板了!
使用Prettier自动格式化
Prettier是一个强大的代码格式化工具
方法一:
在vscode中安装Prettier插件
项目中新生成 .prettierrc文件 (Prettier runtime compiler)
{
"semi": false,
"singleQuote": true,
"trailingComma": "none"
}- useTab:使用tab/空格缩进
- tabWidth:tab是空格的情况下,空格数
- printWidth:当行字符长度。推荐80
- singleQuote:使用单引号还是双引号
- trailingComma:多行输入时,尾部逗号是否添加
- semi尾部是否添加分号
- endOfLine:结束行形式
prettier格式化参考表格https://juejin.cn/post/6938687606687432740
一般我们还会给Prettier添加忽略文件
此时在根目录下新建 .prettierignore 文件
/dist/*
.local
.output.js
/node_modules/**
**/*.svg
**/*.sh
/public/*在设置中 save 中设置保存时自动化
在编辑器中右键有自动格式化选项
方法二:
直接在项目中安装
npm i prettier -D依旧在根目录下新建文件.prettierrc文件 (Prettier runtime compiler),并且编辑保存
此时在根目录下,对文件保存即可
当然方法一、二一步一步保存嫌麻烦,也可以在 package.json文件下实行一步保存命令的配置
"script": {
"prettier": "prettier --write ."
}jsx and tsx
对于tsx、jsx文件,在vscode中Prettier默认不启用
需要在vscode中的setting.json中配置(通过Ctrl+Shift+P 打开 setting.json)
{
"[typescriptreact]": {
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
"[javascriptreact]": {
"editor.defaultFormatter": "esbenp.prettier-vscode"
},
}3.RPC
RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
- 首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接
- 第二,要解决寻址的问题,连接到对应的服务器(如主机或IP地址)以及特定的端口
- 两台服务器之间以 序列化传输数据 + 反序列化得到数据结果
以上是它们连接的建立和数据的传输过程
远程调用的问题
Call ID映射。我们怎么告诉远程机器我们要调用Multiply,而不是Add或者FooBar呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用Multiply,编译器就自动帮我们调用它相应的函数指针。但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。
序列化和反序列化问题
网络传输问题
RPC的大项目适用性:
做一个访问量不大的项目的时候,一台服务器部署上一个应用+数据库也就够了.
访问量稍微大一点之后呢,需要:集群.架设nginx,部署多个服务
再大一点,数据库已经扛不住了,有时候宕机. 那这个时候呢我们需要数据库读写分离,再架设几台数据库服务器,做主从,做分库分表。
再大一点,我们需要拆分模块,拆分项目,比如订单系统分一个项目,但是还是需要切换顶层的nginx.把要重启的服务的流量切到可用服务上. 这个时候就可以使用RPC
所有的服务在启动的时候注册到一个注册机里面,然后顶层处理在接收到nginx的请求时,去注册机找一个可用的服务,并调用接口. 这样子呢,在不加新功能的时候,顶层处理服务我们就不需要动了,那修改了用户信息项目的时候,我们只需要一个个更新用户信息项目的服务群就好了。
部分观点源自https://www.zhihu.com/question/25536695
Native Modules
官方解释
有时,React Native 应用程序需要访问 JavaScript 中默认不可用的原生平台 API,例如用于访问 Apple 或 Google Pay 的原生 API。也许你想重用一些现有的 Objective-C、Swift、Java 或 C++ 库,而不必在 JavaScript 中重新实现它,或者为图像处理之类的事情编写一些高性能、多线程的代码。
NativeModule 系统将 Java/Objective-C/C++(本机)类的实例作为 JS 对象公开给 JavaScript(JS),从而允许您从 JS 内执行任意本机代码。虽然我们不希望此功能成为通常开发过程的一部分,但它的存在至关重要。如果 React Native 没有导出你的 JS 应用程序需要的原生 API,你应该能够自己导出它!
所以我们可以在RN的项目里中看到导入RPC数据使用的是
import {NativeModules} from 'react-native';
const NERCTAppContextModule = NativeModules.NERCTAppContextModule || {};
// iOS审核屏蔽功能
const {
source = ''
} = NERCTAppContextModule;4.Worker
4.1 Web Works
有时候我们需要在客户端进行大量的运算,但又不希望来阻塞我们js主线程
我们可能第一时间考虑的是异步,但是实际上运算量大、运算时间长的任务同样会阻塞我们异步的事件循环,甚至会导致浏览器的假死状态
此时html5的新特性:Web Works就派上用场,它允许我们把如此复杂的逻辑放在浏览器的后台线程中进行处理,让js不阻塞ui线程的渲染
//index.js
const worker = new Worker(new URL('./worker.js', import.meta.url))
worker.postMessage({
question: 'hi worker线程,请告诉我今天的幸运数字是啥'
})
worker.onmessage = (message) => {
console.log('今天幸运数字是:', message.data.answer)
}//worker.js
self.onmessage((message) => {
self.postMessage({
answer: 111
})
})4.2 HTML5中跨文档消息传递
跨文档消息传送(cross-document messaging),有时候也简称为XDM,指的是来自不同域的页面间传递消息。
着是一个bom的api, MDN:window.postMessage。
XDM的核心是postMessage()方法,实际上我们可以使用postMessage()方法进行跨域
postMessage两个参数:
- data:作为
postMessage()第一个参数传入的字符串数据。 - origin:发送消息的文档所在的域,例如“
https://www.w3cmm.com”。
// 跨域发送数据到目标源
window.onload = function () {
document.getElementsByTagName("iframe")[0].contentWindow.postMessage({name: 'wujiang'}, "http://localhost:8090")
}
// 监听目标源发送过来的数据
window.addEventListener('message', function (e) {
if(event.origin=="http://localhost:8080"){//注意origin是发送消息的文档所在的域。
console.log('http://localhost:8090/a.ftl ===> http://localhost:8080/index.jsp')
console.log(e)
}
})4.3 Service Worker
概述
Service workers 本质上充当 Web 应用程序、浏览器与网络(可用时)之间的代理服务器。这个 API 旨在创建有效的离线体验,它会拦截网络请求并根据网络是否可用采取来适当的动作、更新来自服务器的的资源。它还提供入口以推送通知和访问后台同步 API。(在webpack中使用service worker需要安装WorkboxPlugin)
相当于一个服务器与浏览器之间的中间人角色,一个超级拦截器
细节
- 基于web worker
- 在web worker的基础上增加了离线缓存的能力
- 可以拦截全站的请求,并作出相应的动作->由开发者指定的动作
- 由事件驱动的,具有生命周期
- 可以访问cache和indexDB
- 支持推送
- 并且可以让开发者自己控制管理缓存的内容以及版本
- 可以通过 postMessage 接口把数据传递给其他 JS 文件
特点
这个 API 之所以令人兴奋,是因为它可以支持离线体验,让开发者能够全面控制这一体验。(实际上的缓存的效果)
在 Service Worker 出现前,存在能够在网络上为用户提供离线体验的另一个 API,称为 AppCache。 AppCache API 存在的许多相关问题,在设计 Service Worker 时已予以避免。
比如:我们可以以网易新闻的wap页为例,其针对不怎么变化的静态资源开启了sw缓存(例子在里面的第六节部分) https://mp.weixin.qq.com/s/3Ep5pJULvP7WHJvVJNDV-g
使用Service Worker
使用条件:
传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
在Firefox浏览器的用户隐私模式,Service Worker不可用。
- 注册Service Worker(通过
.register方法进行注册,通过.then方法进行回调) - 监听install事件,缓存需要的文件(文件过大,或者一些404时,insall会报错,做好容错处理)
- 拦截请求查看是否已经有需要的数据
// index.js
/* 判断当前浏览器是否支持serviceWorker */
if (navigator.serviceWorker) {
navigator.serviceWorker
.register('sw.js')
.then(function(registration) {
console.log('service worker 注册成功') //服务器被停了之后仍然会打印出来
})
.catch(function(err) {
console.log('servcie worker 注册失败')
})
}sw内可以使用self也可以使用this,每个sw仅会安装一次,除非发生更新
//sw.js
//监听 `install` 事件,回调中缓存所需文件
//event.waitUntil 你可以理解为 new Promise,
//它接受的实际参数只能是一个 promise,因为,caches 和 cache.addAll 返回的都是 Promise,
this.addEventListener('install', e => {
e.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll(['./index.html', './index.js']) //资源列表
}).catch((e) => {
console.warn('err', e);
})
)
})
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
this.addEventListener('fetch', e => {
e.respondWith(
caches.open('my-cache').then((cache) => {
return cache.match(e.request.url)
})
)此时,我们可以在chrome的F12开发者模式中查看 Application 看到 Service Worker 已经启动了
在 Cache 中也可以发现我们所需的文件已被缓存
该示例部署到服务器上之后,用户第一次打开index页面,仍然会从服务器上拉取,之后便去安装Service Worker,执行Service Worker中的install事件,浏览器会再次拉取需要缓存的资源,这一次的缓存是否从网络拉取取决于资源设置的过期时间。当install事件中的资源均拉取成功,Service Worker算是安装成功。如果有一个资源拉取失败,此次Service Worker安装失败,若用户下次再打开该页面,浏览器仍然会重复之前的安装流程尝试安装。
如果index页面的Service Worker安装成功,用户再次打开index页面发起的资源请求便会先经过Service Woker脚本的fetch事件,在该事件中前端开发可以通过编写逻辑控制请求从网络拉取还是从cache中读取或者自己构造一个response丢给前端。
推送消息
if ('serviceWorker' in window.navigator) {
navigator.serviceWorker.register('sw.js', { scope: './' })
.then(function (reg) {
console.log('success', reg);
navigator.serviceWorker.controller &&
navigator.serviceWorker.controller.postMessage("hello im page");
});
}//sw.js
this.addEventListener('message', function (event) {
console.log(event.data);
})接收信息
//sw.js
this.addEventListener('message', function (event) {
event.source.postMessage('我是 sw 将发送信息到 page');
});if ('serviceWorker' in window.navigator) {
navigator.serviceWorker.addEventListener('message', function (e) {
console.log(e.data);
});
}更多通讯方式可以查看https://www.lmcc.top/articles/73.html(包含跨端通讯、两个sw服务通讯)
激活service worker
但是由于Service Worker 的激活是异步的,因此首次注册 Service Worker 的时候可能Service Worker 不会被立刻激活, reg.active 为 Null,系统就会报错。
这个时候我们可以采用Promise内部轮询逻辑进行处理如果 Service Worker 已经被激活那就resolve
if ('serviceWorker' in window.navigator) {
navigator.serviceWorker.register('sw.js')
.then(function (reg) {
return new Promise((resolve, reject) => {
const interval = setInterval(function () {
if (reg.active) {
clearInterval(interval);
resolve(reg.active);
}
}, 50)
})
}).then(sw => {
sw.postMessage("im sw");
})
navigator.serviceWorker.register('sw2.js')
.then(function (reg) {
return new Promise((resolve, reject) => {
const interval = setInterval(function () {
if (reg.active) {
clearInterval(interval);
resolve(reg.active);
}
}, 50)
})
}).then(sw => {
sw.postMessage("im sw2");
})
}生命周期
首次加载
- 注册(register)
- 安装(installing)
- 活动(activated)或者异常(error)
- 可以更新存储在Cache中的key和value
- 空闲(idle)
- 拦截(fetch)或终止(terminated)
- fetch是最重要的一个阶段,拦截代理所有指定的请求,并进行对应的操作
更新加载
- 更新(update)
- 安装(installing)
- 等待活动(waiting)或者异常(error)
生命周期流程图(生命周期章节)(十分推荐!条理清晰)https://xie.infoq.cn/article/d6db2099c0064563a403c51ec
注意的点
1、Service Worker线程运行的是js,有着独立的js环境,不能直接操作DOM树,但可以通过postMessage与其服务的前端页面通信。
2、Service Worker服务的不是单个页面,它服务的是当前网络path下所有的页面,只要当前path 的Service Worker被安装,用户访问当前path下的任意页面均会启动该Service Worker。当一段时间没有事件过来,浏览器会自动停止Service Worker来节约资源,所以Service Worker线程中不能保存需要持久化的信息。
3、Service Worker安装是在后台悄悄执行,更新也是如此。每次新唤起Service Worker线程,它都会去检查Service Worker脚本是否有更新,如有一个字节的变化,它都会新起一个Service Worker线程类似于安装一样去安装新的Service Worker脚本,当旧的Service Worker所服务的页面都关闭后,新的Service Worker便会生效。
更多
service worker 框架库由于google推出直接编写原生sw比较繁琐和复杂所以一些工具框架就出现了,而Workbox相对来说较为优秀
在 Workbox 之前,GoogleChrome 团队较早时间推出过 sw-precache 和 sw-toolbox 库,但是在 GoogleChrome 工程师们看来,workbox 才是真正能方便统一的处理离线能力的更完美的方案,所以停止了对 sw-precache 和 sw-toolbox 的维护。
参考:
https://zhuanlan.zhihu.com/p/115243059
https://x5.tencent.com/product/service-worker.html
https://mp.weixin.qq.com/s/3Ep5pJULvP7WHJvVJNDV-g
https://www.lmcc.top/articles/73.html
https://xie.infoq.cn/article/d6db2099c0064563a403c51ec
5.GIF上报埋点
使用GIF上报的原因:
- 图像类可以解决跨域的问题
- 防止阻塞页面的加载
- 相比png/jpg,gif体积最小,最小的bmp文件需要74B,png需要67B,而合法的gif只需要43B
用gif报埋点大多数采用1*1透明GIF上报
6.jsonserver
可以用于临时模拟后端接口数据,只需要一个json文件即可(jsonserver内置帮你解决了跨域问题,设置了)
使用流程
Install JSON Server
npm install -g json-serverCreate a db.json file with some data
{
"posts": [
{ "id": 1, "title": "json-server", "author": "typicode" }
],
"comments": [
{ "id": 1, "body": "some comment", "postId": 1 }
],
"profile": { "name": "typicode" }
}Start JSON Server
json-server --watch db.json或者指定好端口号
json-server --watch db.json --port 8000Now if you go to http://localhost:3000/posts/1, you’ll get
{ "id": 1, "title": "json-server", "author": "typicode" }增删改查
此时你还可以通过设置请求的method,来增删改查
查 get:
http://localhost:8000/posts/1http://localhost:8000/posts?id=1直接查询到id为1的接口数据(自动检索 )
增加数据 post
axios.post("http://localhost:8000/posts", {
{ "id": 2, "title": "json-server", "author": "typicode" }
})修改数据 put、patch
axios.patch("http://localhost:8000/posts/1", {
{ "title": "json-server" }
})删除数据 delete
在删除数据的时候,若对于不同的数据表,有关联的数据也会一并删除
比如
{
"posts": [
{
"id": 1,
"title": "json-server",
"author": "typicode"
},
{
"id": 2,
"title": "other",
"author": "othercode"
}
],
"comments": [
{
"id": 1,
"body": "some comment",
"postId": 1
}
],
}此时 comments 第一个数据有一个字段是 postId,会和 posts中id为1的数据进行关联,此时删除掉posts的第一条数据,则连带comments的数据也会被删除掉
关联数据
上面再2删除数据中我们可以看到有部分的数据是关联的
如果我们想要在get的时候,带上关联的数据,我们要用 _embed 或者 _expand 字段
_embed :获取向下关联的数据
_expand :获取向上关联的数据
//关联的表是comments
axios.post("http://localhost:8000/posts?_embed=comments").then(res => {
console.log(res)
})
//字段是postId,所以要用post,而不是posts
axios.post("http://localhost:8000/comments?_expand=post").then(res => {
console.log(res)
})7.网络基础知识
区块链
区块链我个人认为就是一个去中心化的一个数据存储中心,里面记录了每个人是什么、拥有什么,并不被某一公司所垄断,而是由世界上每个人通过互联网来维护的存储中心(记账本)
web3
Web 1.0 阶段,用户是单纯的内容消费者,内容由网站提供,网站让你看什么,你就看什么,典型例子就是新闻门户网站。
Web 2.0 阶段,用户是内容的生产者,网站只是一个向用户提供服务的平台,典型的 Web 2.0 平台有维基百科、抖音、微信等等。
Web3 的很多特征还不明确,但是国外很多文章认为,它跟区块链有关。(通过区块链,我们在虚拟世界中得以生存,无法被某个强大的集团 / 公司 垄断)
Web 1.0 是用户读取互联网,Web 2.0 是用户写入互联网,Web3 是用户生活在互联网。
参考:
https://www.ruanyifeng.com/blog/2021/12/web3.html
https://pizzaparty.substack.com/p/the-metaverse-abstracted-reality


